Introduction
Has quarantine got you down? Do you wish you could travel back in time to 2007, when Macbooks cost less than $1,000 and only bulge bracket banks and a handful of hedge funds knew about the impending global financial crisis?
If you played RuneScape in the mid-to-late 2000’s, you can relive the nostalgia on Old School RuneScape (OSRS), which is what I’ve been doing with friends to pass the time recently. The Grand Exchange (GE) was a feature added to the game in November of 2007, which allowed players to buy and sell in-game items under a number of restrictions. There has been some concerted effort online to turn profit through the GE with quantitative methods, and I thought it would be fun to try my hand at ruining the sanctity of a favorite childhood game.
You can find all of the source code on GitHub here.

Background
Available Tools
The current ecosystem of tools and software aimed at this purpose are fairly fragmented. Most notably perhaps is GE-Tracker, a freemium web application that presents some nice dashboards for common trading practices in RuneScape, with a lot of custom web scraping from various websites and APIs (OSBuddy, RSBuddy, Jagex) depending on the item. This is the only service I’ve found that looks actively maintained and accurate. Most other projects devoted to this effort seem to be outdated.
That being said, there are still a number of websites and endpoints available for free use:
- Official Jagex OSRS GE API Endpoint
- OSRS Wiki Documentation on Official API
- OSRS Wiki Main Page
- High Alchemy Calculator
Project Scope
Without the ability to access a large historical dataset to experiment with, we will have to construct one ourselves. There are a few approaches possible to take here. The fastest and easiest way would be to pay for an existing service and download as much data as possible. The next easiest solution would be to run a cronjob to interact with the official API endpoint at regular intervals, and concatenate the responses locally into a single source. The best and most intensive method I can imagine would be to build a web scraper for the pages in the Old School Wiki to backlog historical data with the largest time window possible, and then moving forward at regular but less frequent intervals.
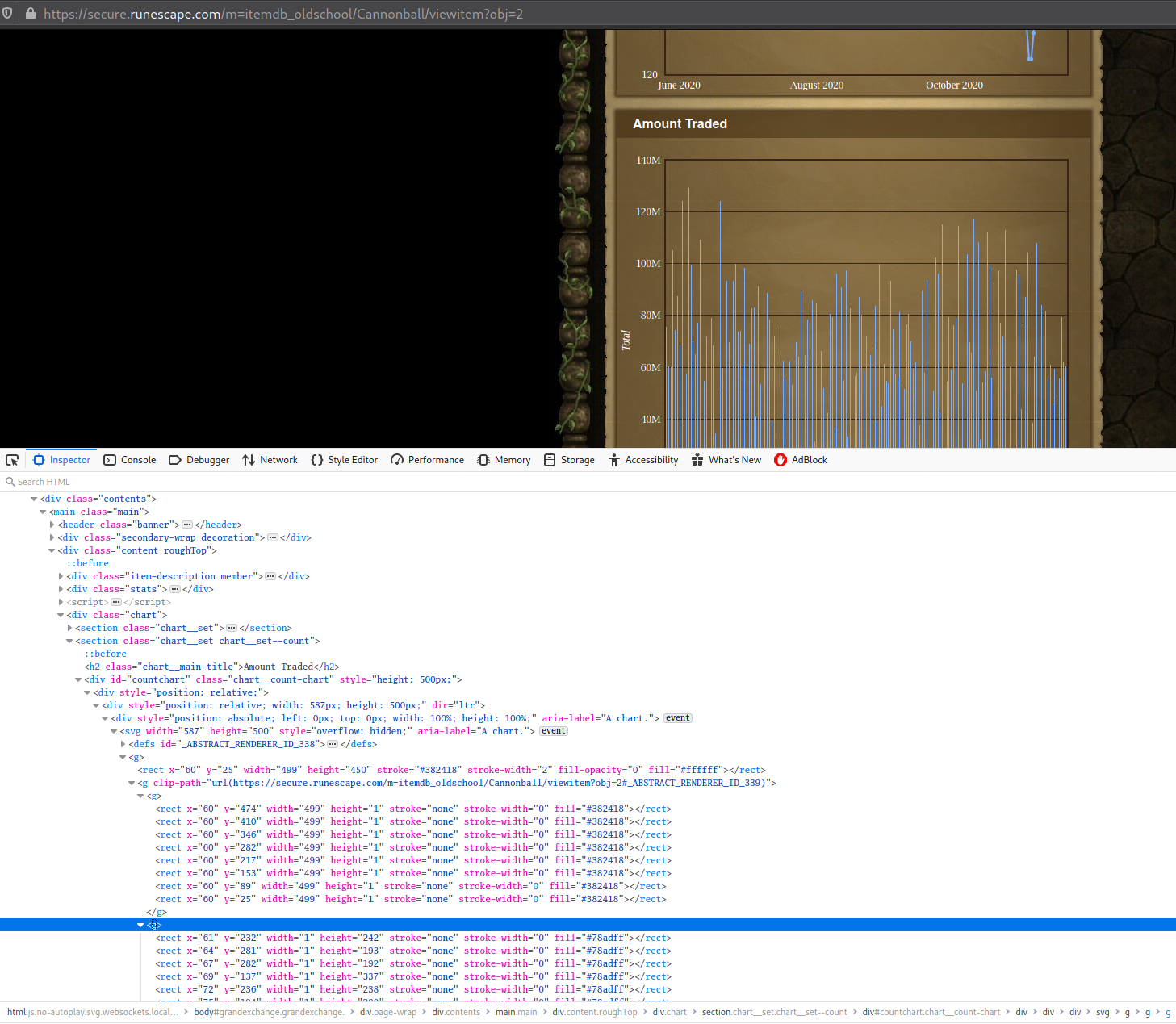
The greatest barrier to this project was lack of documentation. Jagex doesn’t publish any developer docs for their API, which turned out to be semi-reliable at best. What information exists in forums can be useful but is often too old to be relevant in 2020.
The scope of this post will include the collection and preprocessing of GE data, to prepare for analysis. Subsequent posts on the project will cover my work to model market behavior, and hopefully to realize profit from trading strategies.
Web Scraping
Official Endpoints
See the above link for Wiki documentation of the official API. There are a few noteworthy endpoints.
- Top 100 High Volume Items - This contains interesting
information about what items are being traded most frequently in the last week (default view), month, three months, or six
months. Also note the ?list=0 suffix in the URL, as there are other webpages:
- ?list=1 - Valuable Trades (items with highest GP-value appreciation in given time frequency)
- ?list=2 - Price Rises (items with highest percentage appreciation in given time frequency)
- ?list=3 - Price Falls (items with highest percentage depreciation in given time frequency)
- Note: If there is a way to access these pages’ raw data, I haven’t been able to find it. I scrape the HTML for content and href values corresponding to individual item endpoints.
- Last Update Time - This returns an object with the runedate
of the last time the GE database was updated.
- Return Format:
{ "lastConfigUpdateRuneday": 0000 }
- Return Format:
- GE Item Details - This returns
a dictionary of basic price information for a given item.
- URL Format: https://services.runescape.com/m=itemdb_oldschool/api/catalogue/detail.json?item=<ITEM_ID>
- Return Format: See below for an example with the item ‘Cannonball’ (Item ID: 2).
{ "item": { "icon": "https://secure.runescape.com/m=itemdb_oldschool/1606479873357_obj_sprite.gif?id=2", "icon_large": "https://secure.runescape.com/m=itemdb_oldschool/1606479873357_obj_big.gif?id=2", "id": 2, "type": "Default", "typeIcon": "https://www.runescape.com/img/categories/Default", "name": "Cannonball", "description": "Ammo for the Dwarf Cannon.", "members": "true", "current": { "trend": "neutral", "price":137 }, "today": { "trend": "neutral", "price" : 0 }, "day30": { "trend": "negative", "change": "-2.0%" }, "day90": { "trend": "negative", "change": "-17.0%" }, "day180": { "trend": "negative", "change": "-20.0%" } } }
Wiki Endpoints
We could reconstruct the graphs (viewable when expanding the GE section on an item’s Wiki page) by parsing the web page for the graph tags, and this would be the only method viable for some of the third party applications that exist. However, I discovered that the Wiki maintainers offer Lua helper modules to access some of the information they use to construct those graphs directly. This is not publicized anywhere on the Market Watch page, I had to sift through many forum posts to find it. See below for the format of the Exchange Lua Module:
- https://oldschool.runescape.wiki/w/ - base URL
- Exchange:<ITEM_NAME> - basic exchange information, in a simple summary
- Module:Exchange/<ITEM_NAME> - current exchange data (e.g., date, price, volume, metadata)
- Module:Exchange/<ITEM_NAME>/Data - historical price and/or volume (as available) data
We are primarily concerned with the last of the above endpoints, as this page-type minimally returns ‘Unix TimeStamp:Item Price’, and maximally returns ‘Unix TimeStamp:Item Price:Item Volume’ at a daily frequency, depending on the availability of volume information. For context, it seems that volume information was added to web pages on the official website in February of 2018. If problems arise with the Wiki endpoints, an alternative method would be to scrape the official pages’ graphs (HTML <g> tag), as volume data points are graphed.
Similar to the official API, the Wiki requires we construct the URI with an item name (instead of ID). In order to use both sources of information with each other, we need a copy of a dictionary with the ID:Name pairs of tradeable items in the game. Wiki modules are easier to parse because they offer simple support for both web browsing and raw data responses. By appending '?action=raw’ to a given URI, we can retrieve data directly instead of parsing the HTML page. See the below raw examples for the item Bones, that correspond to the above modules:
- https://oldschool.runescape.wiki/w/Exchange:Bones?action=raw
{{ExchangeItem|Bones}} - https://oldschool.runescape.wiki/w/Module:Exchange/Bones?action=raw
return { itemId = 526, icon = 'Bones.png', item = 'Bones', value = 1, limit = 3000, members = false, category = nil, examine = 'Bones are for burying!', hialch = 0, lowalch = 0 } - https://oldschool.runescape.wiki/w/Module:Exchange/Bones/Data?action=raw
return { '1427414400:89', '1427500800:91', '1427587200:92', '1427673600:91', '1427760000:89', ... } - https://oldschool.runescape.wiki/w/Module:GEPrices/data?action=raw
return { ["%LAST_UPDATE%"] = 1606651180.194528, ["%LAST_UPDATE_F%"] = "29 November 2020 11:59:40 (UTC)", ["3rd age amulet"] = 19153331, ["3rd age axe"] = 319351236, ["3rd age bow"] = 656783621, ["3rd age cloak"] = 190955512, ["3rd age druidic cloak"] = 619828196, ... }
Preprocessing
Now that we know where to retrieve the data we want, it’s important to capture and store it in a clean and automatable way so that we can focus on modeling. There were some challenges at this step but nothing out of the ordinary:
- Responses being returned in irregular formats via Lua
- Data from the Top 100 endpoints required HTML parsing
- Some inconsistency with dates returned at the beginning and end of responses
- Saving and merging individual item data into a centralized dataset
- Filling missing price and volume data
Most of the work interacting with the Wiki is done in the call_item_api() function in data.py. Because the response comes from a Lua module, we have to decode the bytes objects and then store it in something pythonic, i.e. a dictionary. Dictionaries are fast and easy to traverse, and can effortlessly be converted to pandas dataframes. We accomplish this by parsing each initial list element for ‘:’ delimiters and adding NaN values whenever there is a missing volume entry. Each function is explained in more detail below.
Project Structure
exploratory.py
This is where I initially tested API calls and data preprocessing for the project. The goal was to be able to reference a subset of desired items and store historical price data in a logical and efficient manner. Please note that I purposefully left this file messy to make my process observable. It shows where I started with the problem. I also tend to use this file as a sketchpad for future ideas, writing down notes alongside in a .txt file.
intermediary.py
This is where I stage functions that I’m cleaning up and evaluating performance. It’s currently empty, but when I begin to time components of this project, I will leave those functions in this file.
data.py
This is where the bulk of the project currently exists. It includes all functions concerned with API requests to Jagex and the Wiki, and the preprocessing and concatenation of that data locally.
-
load_tradeable_item_dict(item_file): Given the name of the .json file, this function will open, convert, and return a pandas dataframe.
-
call_item_api(item_name): Given the name of a tradeable item, this function will send an API request to the OSRS Wiki, format the response, and return it as a dictionary.
-
wiki_dict_to_df(data_dict): Given an input dictionary of data, this function will convert it into a dataframe as well as clean up some properties (reindex with numpy datetime, rename columns).
-
sel_item_sample(df, x): Given an input dataframe of all tradeable items and an integer, this function will randomly sample the items x times and attempt to print truncated pricing data for each item.
-
wiki_api_handler(item_name): Given an input item name, this function handles the API call for sel_item_sample entries, as well as the logic to print a portion of data towards the middle of the returned object (because volume is typically omitted from the beginning and end of data responses).
-
get_top_100_ids(local=True): Given a boolean input, this function will return a list of the top 100 item IDs traded by volume in the last seven days, either from the most recent locally saved copy or from the official API endpoint.
-
get_top_100_names(id_list, ref_df): Given a list of item IDs and a dataframe of all tradeable items, this function will return a list of the corresponding name values for the IDs.
-
id_to_name(item_id, ref_df): Handler function for get_top_100_names, to abstract out the logic of the ID->name conversion.
-
wiki_df_to_csv(item_name, df): Given an item name and dataframe of pricing data for that item, this function will save a local copy of the data as a .csv file in the wiki_historical_data subdirectory of data. This function also safely checks if a copy for a given item already exists, and if so, which table of data is more recent.
-
concat_hist_datasets(): This function iterates through all .csv files in wiki_historical_data and left-joins them as one singular dataset.
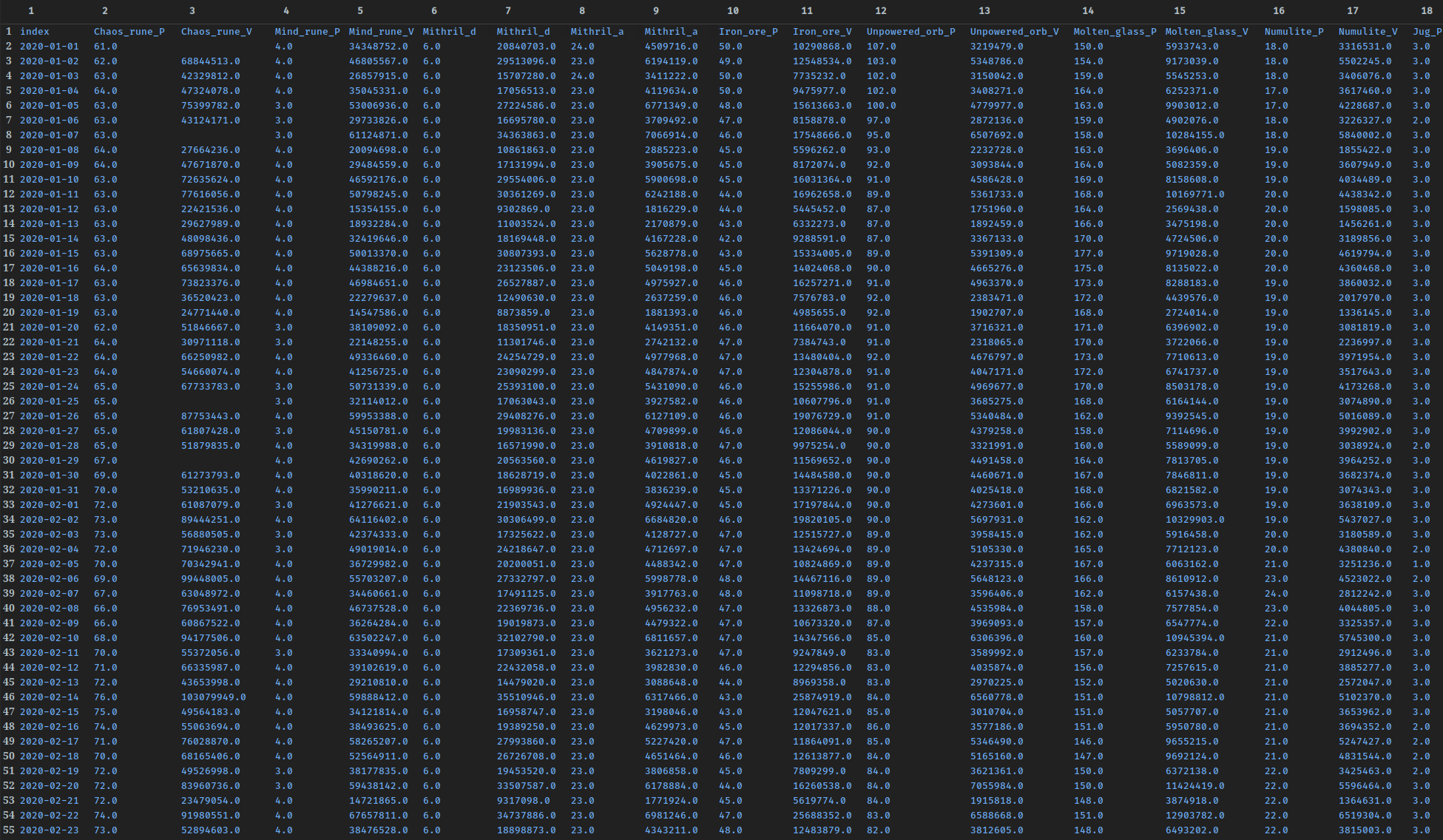
-
slice_hist_dataset(start, end, save_local): Given start/end dates and a boolean input, this function will take the singular dataset created by concat_hist_dataset and return the dataframe between the start and end date (inclusive). The date parameters accept keywords like ‘today’ and empty values default to the beginning/end of the dataset. If save_local is set to True, a local copy of the dataset will also be saved, with the date range in the file name.

augur.py
This has abstracted functions one level higher than data.py. It currently has the following functionality:
- test_tradeable_sample(): Using a dictionary of all tradeable items in the game, randomly select n, and display pricing data retrieved from the Wiki.
- get_single_data_csv(): Requests, preprocesses, and stores a .csv file of data for a single specified item.
- get_t100_data_csv(): Requests, preprocesses, and stores .csv files of data for the top 100 highest volume items on the exchange in the last seven days (configurable for local item references).
- merge_historical_db(): Concatenates all local historical data retrieved from the Wiki into a centralized table.
- slice_historical_db(): Given a start and end date, return (and/or save) the sliced subset of the table.
main.py
This is the file that executes augur.py. If in future iterations there were multiple Python files that needed to interact with each other, they would be imported here. You could also run the program from the augur.py file itself, however centralizing project execution here reduces complexity while I continue to work on the project.
data/metadata/
The directory where data required for program functionality is stored. Currently, the only file merged to the repository is the dictionary of all tradeable items and their metadata. In the future, lists of item subclasses will be added here.
data/historical_wiki_data
The directory where .csv files of historical data for individual items are stored. Note that the merged table exists in the root of the ‘data’ directory.
Testing Functionality
Python Dependencies
In order to execute the program, you will need a working Python interpreter (>= 3.6) with a one non-standard library. You should already have an installed version of Python 3. From a terminal, you can check your version and interpreter location with:
python3 —version && which python3MacOS
If the above command returns an error or a version less than 3.6.0, you can use homebrew to install a more recent version (for directions on installing homebrew, see here):
brew install python3
brew install pip3Linux
Use your system’s package manager (apt-get, pacman, etc.) to install:
sudo pacman -S python python-pipPackage Dependencies
To execute the main program, the only necessary package to install is pandas.
To install, use the Python package manager pip3 (some systems may alias as simply pip):
sudo pip3 install pandasExecuting the Program
Currently, it is required to explicitly change the function call in main.py to any desired function from augur.py.
From the directory osrs-augur, enter the following command to run:
python3 main.pyMoving Forward
- Price Discrepancies - Third-party clients that give users plugins for extra UI functionality can collect information about what their users are trading. This means that they have some insight into the real intra-day prices and supply/demand that Jagex does not. There is potential to study the nature of price discrepancies between the official API and client-based plugins.
- Visualization - Now that we have the ability to store historical GE data for any given items, it would be interesting to create some multivariate graphs for the time-series information accumulated.
- Cloud Deployment - To reduce any manual database maintenance, it would be fairly easy to move the database construction step to a platform like AWS. The functionality in data.py could be tweaked to call the Wiki regularly for a subset of items and add those new rows to the full database in an S3 bucket or DynamoDB table. For intra-day pricing, the same setup applies, but would probably be stored in a separate storage object.
- Improving Storage Design - Either transferring to a cloud storage object or possibly running a simple Postgres database in a Docker container may simplify development for the future, if the schema is unlikely to change. Also, writing the central table of historical data could be done more quickly by checking if an existing attribute is in the list of column headers, and then checking its final index that contains non-null price and volume values against the final index value of the other vector.
- Volume Interpolation - This can get complicated quickly, but there is a lot of potential work that could be done interpolating missing volume data, as there are some consistent behaviors between items. Missing single entries between 2018 and 2020 can (and should) be estimated easily in a linear manner. Volume data must be collected at a lag by the Wiki, because for any given response it is missing in the final 5-10 rows. Finally, there may be other sources of data online to help approximate some volume information leading up to the official support in February of 2018.
- Modeling - This is where I personally believe the bulk of work ought to be done for the project. Starting with fundamental statistical approaches before moving on to more recently explored ML approaches should be fun. Two ideas at the top of my list to implement are: marking signals for documented major events (game updates and patches, special event start and end dates), and investigating if there are any significant seasonality components to the value of particular item subsets. Forecasting performance and in-game profit are also two of the only ways I can quantify any sort of ‘success’ with the project.